If you spend enough time around AI companies, eventually someone will say:
“We use RAG.”
For many people outside the AI industry, the term sounds mysterious or overly technical. But RAG is actually one of the most important concepts in modern AI systems. Especially Voice AI.
And in many ways, it solves one of the biggest weaknesses of large language models.
What Does RAG Stand For?
RAG stands for:
Retrieval-Augmented Generation
That sounds complicated, but the idea is surprisingly simple.
Instead of asking an AI model to rely only on what it learned during training, RAG allows the AI to retrieve relevant information from external sources while the conversation is happening.
In other words:
The AI doesn’t have to memorize everything.
It can look things up.
Why This Matters
By default, most large language models are frozen in time.
Even advanced models may:
- Not know your company policies
- Not know your pricing
- Not know your inventory
- Not know the latest support documentation
- Not know customer-specific data
- Hallucinate answers when uncertain
This becomes a major problem in production Voice AI systems.
Imagine a cleaning company AI receptionist telling a customer:
“Yes, every team has a ladder for those hard to reach areas.”
…when they actually does not.
That is not just an AI problem.
That is an operational problem.
RAG helps solve this.
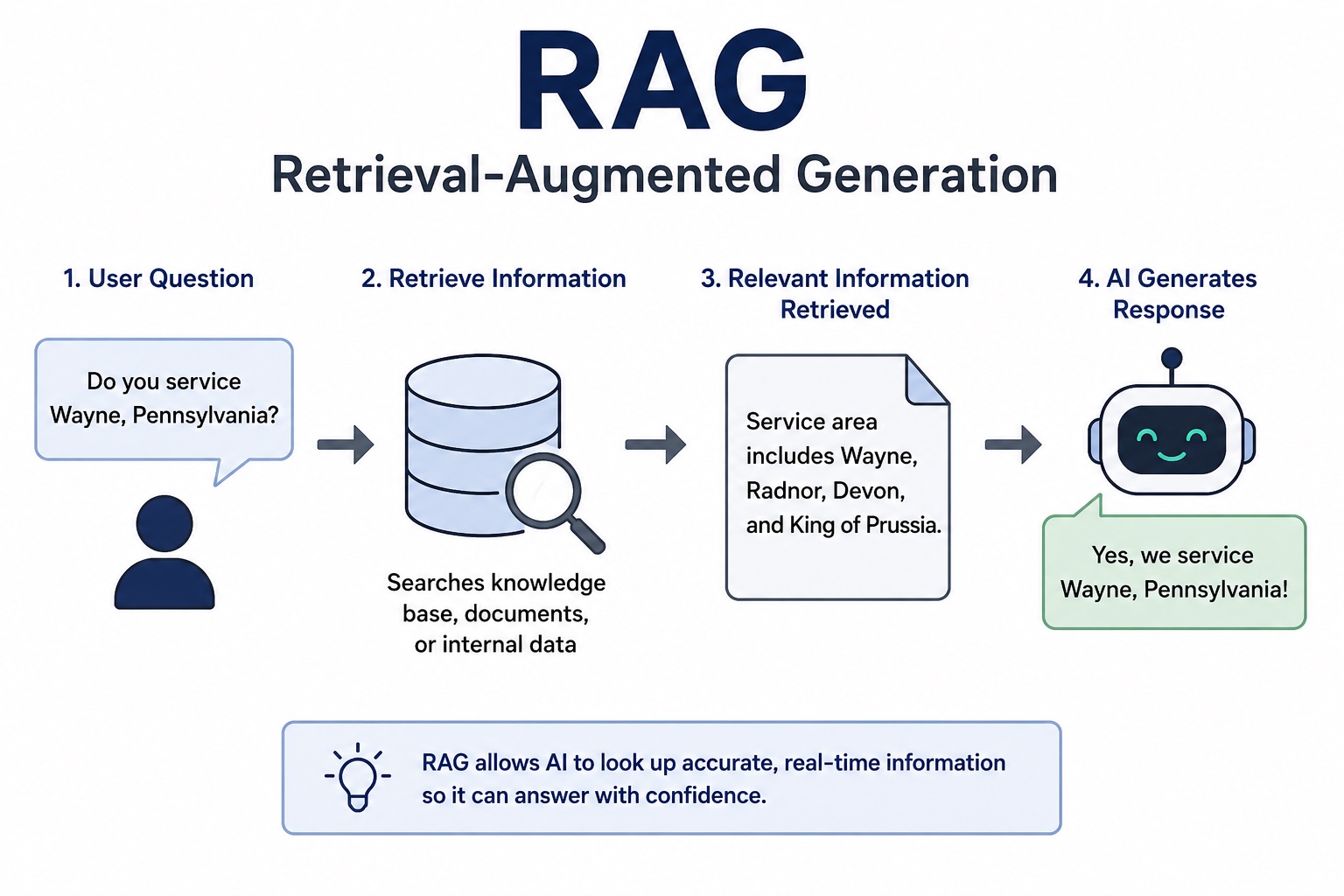
How RAG Works
At a high level, a RAG system works like this:
Step 1: User asks a question
“Do you service Wayne, Pennsylvania?”
Step 2: System searches for relevant information
The AI searches a knowledge base, CRM, vector database, documentation system, or internal company data.
Step 3: Relevant information is retrieved
For example:
“Service area includes Wayne, Radnor, Devon, and King of Prussia.”
Step 4: The AI generates a response using that information
Instead of guessing, the AI now answers with grounded context.
Why RAG Became So Important
Early AI demos often relied entirely on prompts.
Teams would stuff huge amounts of information into the system prompt:
- Pricing
- FAQs
- Policies
- Objection handling
- Documentation
- Product details
- Support flows
Over time, prompts became massive.
This created several problems:
- Increased latency
- Higher token costs
- More prompt drift
- Conflicting instructions
- Reduced reliability
- Larger cognitive load on the model
RAG emerged as a cleaner architecture.
Instead of forcing the model to remember everything at once, relevant information could be fetched dynamically only when needed.
This dramatically improved scalability.
RAG in Voice AI
RAG is especially important in Voice AI because callers expect answers immediately.
A Voice AI agent may need to retrieve:
- Appointment availability
- Account details
- Order status
- Internal policies
- Troubleshooting guides
- Product compatibility
- Real-time pricing
- CRM notes
And it must do all of this fast enough to maintain conversational flow.
This creates a difficult engineering challenge:
Every retrieval step adds time.
If retrieval is slow, the caller experiences hesitation.
That is why Voice AI teams obsess over response time and latency.
The AI might be “smart,” but if it pauses for four seconds before answering, trust starts collapsing almost immediately.
RAG vs Fine-Tuning
People often confuse RAG with fine-tuning, but they solve different problems.
Fine-Tuning
Fine-tuning changes the model itself.
You train the model on additional examples so its behavior changes permanently.
Good for:
- Tone
- Style
- Structured behavior
- Specialized language patterns
RAG
RAG keeps the model the same but feeds it external information during runtime.
Good for:
- Dynamic information
- Frequently changing data
- Company knowledge
- Customer-specific information
- Real-time retrieval
In practice, many production systems use both.
The Hidden Complexity of RAG
From the outside, RAG sounds easy:
“Just let the AI search documents.”
But production RAG systems become extremely complicated.
Questions quickly emerge:
- Which documents should be searchable?
- How fresh is the data?
- What happens when documents conflict?
- What if retrieval returns irrelevant information?
- What if retrieval fails entirely?
- How much context should be injected?
- How do you rank relevance?
- How do you prevent prompt injection attacks?
- How do you maintain low latency?
The retrieval layer itself often becomes its own product category.
Vector Databases and Embeddings
Most modern RAG systems rely on something called embeddings.
An embedding converts text into numerical representations that capture semantic meaning.
This allows systems to search based on meaning, not just keywords.
For example:
A caller asking:
“Do you fix leaking pipes?”
might retrieve documentation containing:
“We provide residential plumbing repair services.”
Even though the exact words differ, the meanings are related.
Vector databases are optimized to perform these similarity searches quickly.
Popular vector databases include:
- Pinecone
- Weaviate
- Chroma
- Qdrant
- Milvus
Why RAG Is Not Magic
RAG improves accuracy dramatically, but it does not eliminate mistakes.
A bad retrieval system can still produce bad answers.
In fact, one of the most dangerous situations is when the AI retrieves partially relevant information and confidently answers incorrectly.
This is why observability matters so much in Voice AI systems.
Teams increasingly need visibility into:
- What was retrieved
- Why it was retrieved
- What context was injected
- How the model interpreted it
- Whether the retrieval improved or harmed the response
The Bigger Shift
RAG represents a broader shift in AI architecture.
The industry is moving away from:
“The model knows everything.”
toward:
“The model orchestrates information.”
That distinction matters.
Modern AI systems increasingly behave less like standalone brains and more like real-time reasoning layers sitting on top of external tools, APIs, databases, and knowledge systems.
RAG is one of the foundational technologies enabling that transition.
And for Voice AI in particular, it is becoming almost impossible to avoid.