Why Small Language Models May Become One of the Most Important Parts of AI Infrastructure
For the past two years, most of the AI conversation has focused on LLMs (Large Language Models.)
Think GPT-4. Claude. Gemini. Llama.
Bigger models. More parameters. More intelligence.
But something interesting is beginning to happen inside production AI systems:
Many companies are quietly discovering they do not actually need a massive frontier model for every task.
In many cases, using an LLM for everything is becoming economically inefficient, operationally slow, and architecturally unnecessary.
That is where SLMs come in.
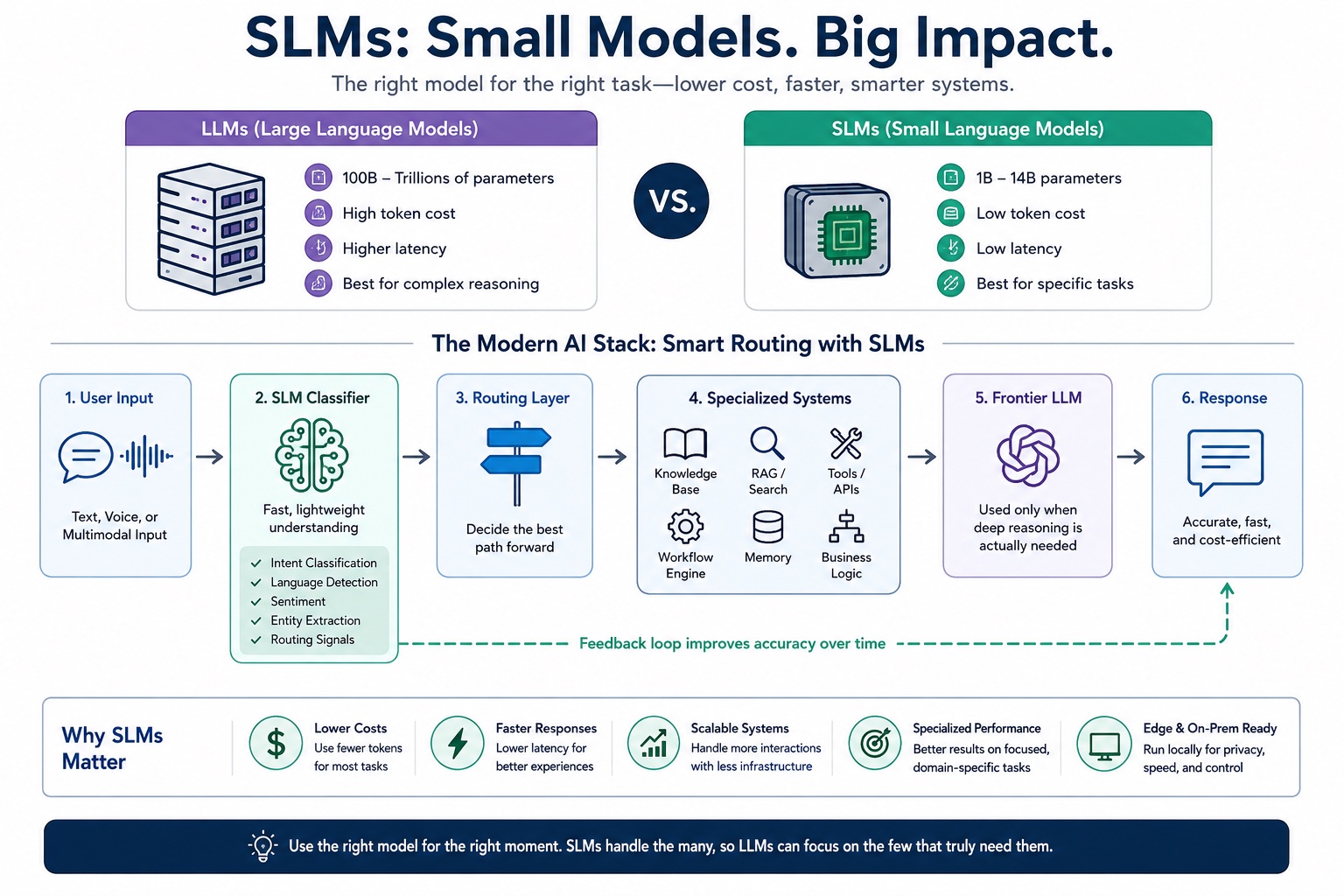
What Is an SLM?
SLM stands for Small Language Model.
There is no perfectly agreed-upon definition, but generally:
- LLMs are massive general-purpose models with hundreds of billions or trillions of parameters
- SLMs are smaller, more specialized models optimized for speed, cost, efficiency, or targeted reasoning
An SLM might have:
- 1B parameters
- 3B parameters
- 7B parameters
- 14B parameters
Compared to frontier LLMs, these models are dramatically smaller and cheaper to operate.
But smaller does not necessarily mean worse.
In fact, for many real-world tasks, SLMs can outperform larger models because they are focused, constrained, and easier to optimize.
Why SLMs Matter
Early AI adoption often looked like this:
“Just send everything to GPT-4.”
That worked when:
- token costs were lower
- usage volumes were small
- latency expectations were forgiving
- companies were experimenting rather than operating at scale
But production systems behave differently.
As usage increases, companies begin noticing several things:
- Token costs compound quickly
- Latency becomes operationally important
- Long prompts become expensive
- Context windows grow inefficient
- Real-time systems become difficult to scale economically
This is especially true in Voice AI.
A conversational system processing thousands of live calls per day cannot always afford to use a frontier LLM for every single operation.
Sometimes the “AI” does not need deep reasoning at all.
Sometimes it simply needs to:
- classify intent
- extract a date
- determine sentiment
- identify language
- summarize a transcript
- route a workflow
- detect escalation risk
- validate formatting
- perform lightweight retrieval
These are ideal SLM workloads.
The Emerging AI Stack
A lot of people still think of AI systems as:
User → LLM → Response
But modern production architectures increasingly look more like this:
User Input
↓
SLM Classifier
↓
Routing Layer
↓
Specialized Systems
↓
Frontier LLM (only when necessary)
↓
Response
This is becoming one of the biggest architectural shifts in AI engineering.
Instead of using one giant model for everything, companies are building layered systems where smaller models handle the majority of operational work.
In many ways, AI infrastructure is beginning to resemble distributed systems engineering more than simple chatbot deployment.
The expensive model only gets invoked when higher-level reasoning is actually required.
This approach can dramatically reduce:
- inference cost
- response latency
- token consumption
- infrastructure load
while improving consistency and operational predictability.
SLMs Are Not Just “Cheaper GPTs”
This is an important distinction.
The goal of an SLM is not necessarily to compete directly with GPT-4 on generalized intelligence.
The goal is specialization.
A well-trained SLM can become extremely good at:
- medical entity extraction
- telecom call classification
- legal/financial document tagging
- voice sentiment analysis
- support ticket routing
- fraud detection
- voicemail summarization
- scheduling workflows
- command interpretation
In many of these cases, a smaller focused model can outperform a general-purpose frontier model because:
- the task scope is narrower
- the behavior is more deterministic
- less contextual reasoning is required
- the operational constraints are clearer
This is similar to the difference between:
- a general practitioner
- and a specialist surgeon
Bigger intelligence is not always the most efficient tool.
Why Voice AI Will Likely Accelerate SLM Adoption
Voice AI systems create unique operational pressures.
Unlike chat systems, voice systems operate in real time.
Milliseconds matter.
Every additional second of latency changes how humans perceive intelligence and trust.
This creates strong pressure toward:
- faster inference
- lower token usage
- lightweight orchestration
- deterministic behavior
- lower operational cost per interaction
As Voice AI scales, many architectures will likely evolve toward:
- SLMs handling conversational state classification
- SLMs performing extraction and routing
- frontier LLMs reserved for complex reasoning moments
- local edge inference for ultra-low latency tasks
The economics almost force this direction.
Where People Can Find SLMs
One reason many people are unfamiliar with SLMs is because most public attention still focuses on flagship models.
But there are now many excellent small-model ecosystems emerging.
Some notable examples include models from:
- Microsoft Phi family
- Meta Llama small variants
- Google Gemma
- Mistral AI Ministral / Mistral Small
- Alibaba Cloud Qwen small variants
Many can be found through:
Some can even run locally on consumer hardware.
That changes the economics considerably.
The Future May Not Be One Giant Model
One of the biggest misconceptions in AI right now is the assumption that larger models always represent the end state.
But production systems rarely evolve toward maximum theoretical capability.
They evolve toward:
- efficiency
- reliability
- specialization
- orchestration
- economics
The future AI stack may not be:
one massive omniscient model
It may instead become networks of specialized models working together
Some tiny.
Some local.
Some domain-specific.
Some frontier-scale.
In many ways, AI infrastructure is beginning to resemble distributed systems engineering more than simple chatbot deployment.
And SLMs are becoming one of the most important building blocks in that transition.
#AI #openai #SLM