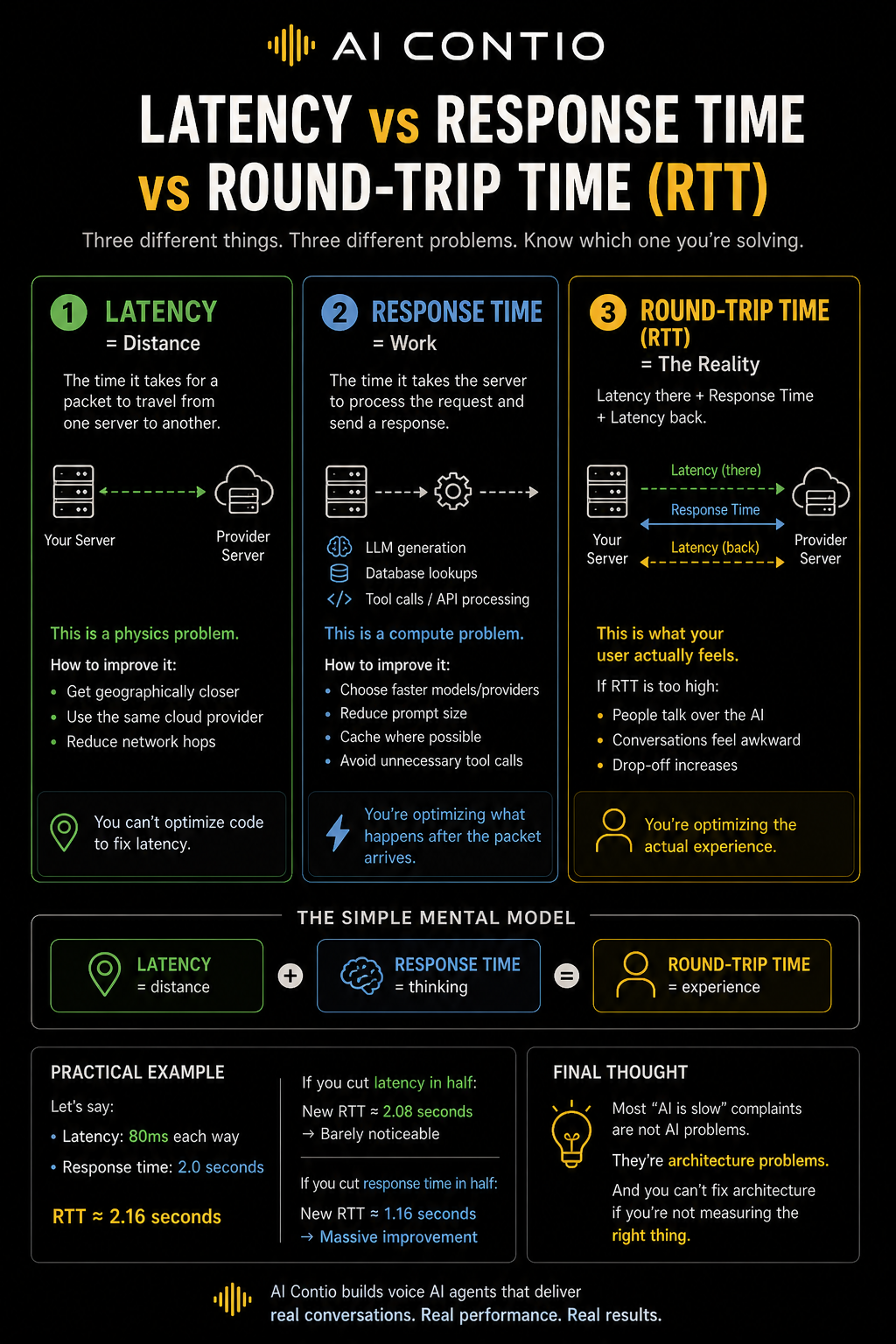
Sometimes when using Voice AI the response simply feels “slow”. Typically that manifests as dead air in the conversation. Too much dead air can kill a Voice AI interaction. Some providers solve this with ‘comfort noise’ like background office noise or even vocal tics like “uhhhhh” or “hmmmm, let me see.” Basically delay tactics. The real solution is to lower the round trip time (RTT) of the response, but a lot of people are mixing together three completely different concepts:
Latency. Response Time. Round-Trip Time.
If you don’t separate them, you can’t fix the problem.
1. Latency = Distance (Physics Problem)
Definition:
Latency is the time it takes for a packet to travel from Point A to Point B. That’s it. If you were to ‘ping’ from your server to their server, the latency is half the ping time. (Ping is measured in miliseconds and is the full round trip time. If you ping from your server to their server and receive an average ping time of 30ms, that means that one-way is 15ms.).
That’s it. No processing. No thinking. Just physical travel time.
Think:
- Your server → OpenAI
- Your server → ElevenLabs
- Twilio → your webhook
This is fundamentally a physics problem.
How to Improve Latency
Luckily it’s fairly easy to ‘fix’ latency. You don’t fix latency in code. Latency in *most* cases is strictly geographic. If you are in Toronto, Canada and their server is in Paris, France, that packet has to travel nearly 4,000 miles. There are simply physical limitations to how quickly a packet can there and back. Either switch providers to one more geographically close to you or find server space closer to your vendor.
Primary fixes for Latency:
- Get geographically closer
- Use the same cloud provider (e.g., stay inside Google Cloud or Amazon Web Services)
- Reduce network hops
You fix where things reside.
2. Response Time = Work (Compute Problem)
Definition:
Response time is how long the receiving system takes to process the request and send a response. The analogy here is you place your order at the drive through. The Response Time is how long it takes you to receive your french fries. Once you’ve sent an API request to a provider, how long it takes for them to process that request and respond is their response time.
Response time includes:
- API processing
- LLM generation time
- Database lookups
- Tool calls
This is where provider differences show up.
Example:
- Twilio vs Telnyx
- OpenAI vs Anthropic
- Different models
- Different load conditions
How to Improve Response Time
Response time can be harder to fix and can even include trial and error. Recently I was using a Voice AI platform and had terrible RTT manifesting in long delays in the audio response. I looked at the ping times and they were decent. I looked at the API calls and they were efficient and the LLM response were brief. I then tried the actual text-to-speech (TTS) engine. Ironically I switched from the native TTS to a third party and it dramatically improved the quality of the AI Voice call.
You can:
- Choose faster providers/models
- Reduce prompt size
- Reduce response size
- Cache where possible
- Avoid unnecessary tool calls
You’re optimizing what happens after the packet arrives at it’s destination.
3. Round-Trip Time (RTT) = The Reality Users Feel
Definition:
RTT = Latency (there) + Response Time + Latency (back)
This is what your user actually experiences and in Voice AI, this is everything. If RTT gets too high:
- People talk over the AI
- Conversations feel awkward
- Drop-off increases because humans don’t handle silence well
Practical Example
Let’s say:
- Latency: 80ms each way
- Response time: 2.0 seconds
RTT ≈ 2.16 seconds
If you cut latency in half:
- New RTT ≈ 2.08 seconds
→ Barely noticeable
If you cut response time in half:
- New RTT ≈ 1.16 seconds
→ Massive improvement
Conclusion:
Don’t optimize the wrong leg of the journey. Recognize where the issue reside and solve for the right problem.
The Simple Mental Model
- Latency = distance
- Response time = thinking
- RTT = experience
Final Thought
Many Voice AI carriers are talking about their ‘low latency’. It’s only low if you are physically near them. What they really need to focus on is their response time. Also, the carrier is only part of the overall customer experience. You have to take that audio and turn it into text (speech-to-text STT) and then feed that text to the LLM. Get the text response from the LLM and turn that to speech (text-to-speech TTS) and then put that audio back on the public telephone network. So many hops along the way.
RTT is an architecture problems.
And you can’t fix architecture if you’re not measuring the right thing.
#AI #AI Voice #telnyx #twilio